Evaluation Examples Are Not Equally Informative: How Should That Change NLP Leaderboards?
Welcome to the project page for our ACL 2021 paper: Evaluation Examples Are Not Equally Informative: How Should That Change NLP Leaderboards?.
Come chat with us at our poster session on Wednesday, August 4 at 00:00-2:00 UTC+0 (Tuesday, August 3 at 5PM PST).
Abstract
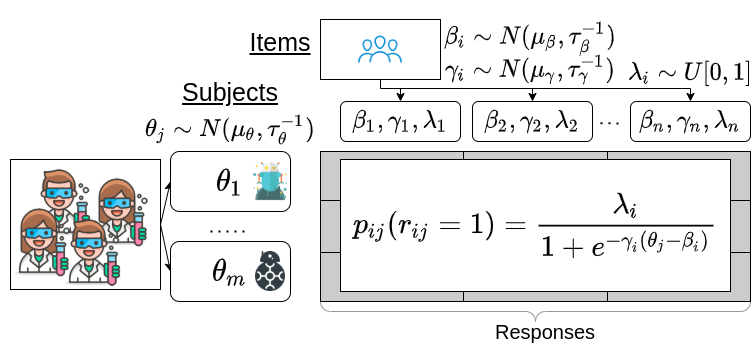
Leaderboards are widely used in NLP and push the field forward. While leaderboards are a straightforward ranking of NLP models, this simplicity can mask nuances in evaluation items (examples) and subjects (NLP models). Rather than replace leaderboards, we advocate a re-imagining so that they better highlight if and where progress is made. Building on educational testing, we create a Bayesian leaderboard model where latent subject skill and latent item difficulty predict correct responses. Using this model, we analyze the ranking reliability of leaderboards. Afterwards, we show the model can guide what to annotate, identify annotation errors, detect overfitting, and identify informative examples. We conclude with recommendations for future benchmark tasks.
Citation
If you cite our paper, please use this citation:
@inproceedings{rodriguez2021leaderboard,
title = "Evaluation Examples Are Not Equally Informative: How Should That Change NLP Leaderboards?",
author = "Pedro Rodriguez and Joe Barrow and Alexander Hoyle and John P. Lalor and Robin Jia and Jordan Boyd-Graber",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics",
year = "2021",
url = "https://aclanthology.org/2021.acl-long.346",
doi = "10.18653/v1/2021.acl-long.346",
publisher = "Association for Computational Linguistics"
}Code
We have open sourced our model and paper code at the links below. Instructions to reproduce our results are in each respective repository.
- Model code: github.com/facebookresearch/irt-leaderboard
- Paper latex: github.com/entilzha/publications
Data
- Full data (decompressed 20-25GB): https://obj.umiacs.umd.edu/acl2021-leaderboard/leaderboard-data-all.tar.gz
- Data minus linear models (decompressed 6GB): https://obj.umiacs.umd.edu/acl2021-leaderboard/leaderboard-data-minus-linear.tar.gz
- Only IRT model and data (decompressed 1GB): https://obj.umiacs.umd.edu/acl2021-leaderboard/leaderboard-data-only-irt.tar.gz
Contact
Please contact Pedro Rodriguez at me@pedro.ai