Information Seeking in the Spirit of Learning: a Dataset for Conversational Curiosity
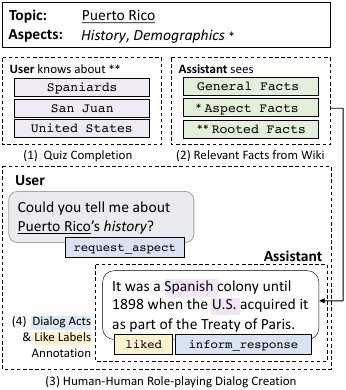
Welcome to the project page for our EMNLP 2020 paper: Information Seeking in the Spirit of Learning: a Dataset for Conversational Curiosity. Our paper introduces the Curiosity dataset which consists of 14K dialogs with fine-grained knowledge groundings, dialog act annotations, and other auxiliary annotations.
You can browse and explore the curiosity dataset at datasets.pedro.ai/dataset/curiosity.
Abstract
Open-ended human learning and information-seeking are increasingly mediated by digital assistants. However, such systems often ignore the user’s pre-existing knowledge. Assuming a correlation between engagement and user responses such as “liking” messages or asking followup questions, we design a Wizard-of-Oz dialog task that tests the hypothesis that engagement increases when users are presented with facts related to what they know. Through crowd-sourcing of this experiment, we collect and release 14K dialogs (181K utterances) where users and assistants converse about geographic topics like geopolitical entities and locations. This dataset is annotated with pre-existing user knowledge, message-level dialog acts, grounding to Wikipedia, and user reactions to messages. Responses using a user’s prior knowledge increase engagement. We incorporate this knowledge into a multi-task model that reproduces human assistant policies and improves over a BERT content model by 13 mean reciprocal rank points.
Citation
If you cite our paper, please use this citation:
@inproceedings{rodriguez2020curiosity,
title = "Information Seeking in the Spirit of Learning: A Dataset for Conversational Curiosity",
author = "Rodriguez, Pedro and
Crook, Paul and
Moon, Seungwhan and
Wang, Zhiguang",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.655",
doi = "10.18653/v1/2020.emnlp-main.655",
pages = "8153--8172",
}Data
You can download the dataset files in one of two ways:
- Cloning the model code which includes the dataset via git lfs.
- Using the direct links below.
Download Links
- Curiosity Dialogs (All)
- Curiosity Dialogs (Train)
- Curiosity Dialogs (Val)
- Curiosity Dialogs (Test)
- Curiosity Dialogs (Zero-shot)
- Fact Entity Links
- Wikipedia2Vec Embeddings in Model
- Wikipedia Sqlite Fact DB
Code
We have open sourced our model and paper code at the links below. Instructions to reproduce our results are in each respective repository.
- Model code: github.com/facebookresearch/curiosity
- Paper code: github.com/entilzha/publications
Contact
Please contact Pedro Rodriguez at me@pedro.ai