Entropy and KL Divergence
Introduction
The KL divergence is short for the Kullback-Leibler Divergence discovered by Solomon Kullback and Richard Leibler in 1951. Semantically, divergence means the amount by which something is diverging, and diverging in turn means to lie in different directions from a different point. In the case of KL divergence we are interested in how divergent (different) two probability distributions are to each other.
This post will review examples, intuition, and mathematics that are necessary to understand the KL divergence, namely entropy and cross entropy, then do the same for the KL divergence itself.
Motivating Example
To give a simple concrete example, lets suppose that we are given two of normal distributions and where a normal distribution is defined as . Our goal is to find a new approximating normal distribution that best fits the sum of the original normal distributions.
Here we run into a problem: how do we define the quality of fit of the original distribution to the new distribution? For example, would it be better to smooth out the approximating normal distribution across the two original modes or to fully cover one mode while leaving the other one uncovered? Visually, this corresponds to preferring option A or option B in the following plots:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sb
import scipy
from scipy import statsx = np.linspace(-10, 10, num=300)
norm_1 = stats.norm.pdf(x, loc=3) / 2
norm_2 = stats.norm.pdf(x, loc=-3) / 2
two_norms = norm_1 + norm_2approx_norm_middle = stats.norm.pdf(x, loc=0, scale=4)
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
plt.plot(x, two_norms, label='P=(N(-3, 1) + N(3, 1))/2')
plt.plot(x, approx_norm_middle, label='Q=N(0, 4)')
plt.title('Option A')
plt.legend(loc=2)
approx_norm_side = stats.norm.pdf(x, loc=3, scale=2)
plt.subplot(1, 2, 2)
plt.plot(x, two_norms, label='P=(N(-3, 1) + N(3, 1))/2')
plt.plot(x, approx_norm_side, label='Q=N(3, 2)')
plt.title(f'Option B')
plt.legend(loc=2)
plt.show()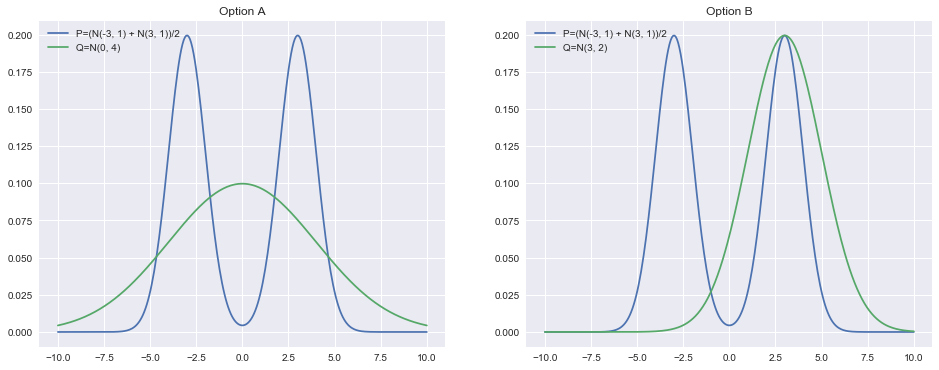
To give one answer to this question lets first label the original distribution (average of two normals) and the distribution we are using to approximate it . The view that the KL divergence takes is of asking “if I gave someone only , how much additional information would they need to know everything about ?”
The usefulness of this formulation becomes obvious if you consider trying to approximate a very complex distribution with a simpler distribution . You want to know how bad your new approximation is!. To do so we first need to visit the concepts of entropy and cross entropy though.
Entropy
We can formalize this notion of counting the information contained in a distribution by computing its entropy. An intuitive way to understand what entropy means is by viewing it as the number of bits needed to encode some piece of information. For example, if I toss a coin three times I can have complete information of the events that occurred using only three bits (a 1 or 0 for each heads/tails).
We are interested in the entropy of probability distributions which is defined as:
That is all well and good, but what does it mean? Lets start with a simple concrete example. Suppose we have a simple probability distribution over the likelihood of a coin flip resulting in heads or tails . Plugging this into the formula for entropy we get
Setting results in , and setting results in . We can also observe that as , . This shows that if is very close to (where almost all the coin tosses will be heads), then the entropy is low. If is close to then the entropy is at its peak.
Conceptually this makes sense since there is more information in a sequence of coin tosses where the results are mixed rather than one where they are all the same. You can see this by considering the case where the distribution generates heads with likelihood and tails with likelihood . A naive way to convey this information would be to report a for each heads and a for each tails. One way to represent this more efficiently would be to encode every two heads as a , one heads as , and tails as (note that there is no symbol otherwise you would not be able to tell whether meant a tails then a heads or one heads). This means that for every pair of heads we can represent it in half as many bits, but what about the other cases? We only need to represent a single heads when a tails occurs for which the overall cost of this combination is bits for 2 numbers. Take an example of encoding 99 heads and 1 tails: it would use bits to represent nearly all the heads and bits for the remaining heads and tails for a grand total of bits. This is much less than bits and its all possible because the entropy is low!
Now lets formalize the intuition from that example and return to the normal definition of entropy to explain why the entropy is defined that way.
To assist us lets define an information function in terms of an event and probability of that event . How much information is acquired due to the observation of event ? Consider the properties of the information function
- When goes up then goes down. When goes down then goes up. This is sensible because under the coin toss example making a particular event more likely caused the entropy to go down and vice versa.
- : Information cannot be negative, also sensible.
- : Events that always occur contain no information. This makes sense since as we took the limit of , .
- : Information due to independent events is additive.
To see why property (4) is crucial and true consider two individual events. If the first event could result in one of equally likely outcomes and the second event in equally likely outcomes then there are possible outcomes of both events combined. From information theory we know that bits and bits are required to encode events and respectively. From the property of logarithms we know that so logarithmic functions preserve (4)! If we recall that the events are equally likely with some probability then we can realize that is the number of possible outcomes so it corresponds to choosing (this generalizes with some more math). If we sample points then we observe each outcome on average . Thus the total amount of information received is:
Finally note that if we want the average amount of information per event that is simply which is exactly the expression for entropy
Cross Entropy
We have now seen that entropy gives us a way to quantify the information content of a given probability distribution, but what about the information content of one distribution relative to another? The cross entropy which is defined similarly to the regular entropy is used to calculate this. It quantifies the amount of information required to encode information coming from a probability distribution by using a different/wrong distribution . In particular, we want to know the average number of bits needed to encode some outcomes from with the probability distribution where is the length of the code for in bits. To arrive at the definition for cross entropy we will take the expectation of this length over the probability distribution .
With the definition of the cross entropy we can now move onto combining it with the entropy to arrive at the KL divergence.
KL Divergence
Now armed with the definitions for entropy and cross entropy we are ready to return to defining the KL divergence. Recall that represents the amount of information needed to encode with . Also recall that is the amount of information necessary to encode . Knowing these makes defining the KL divergence trivial as simply the amount of information needed to encode with minus the amount of information to encode with itself:
With the origin and derivation of the KL divergence clear now, lets get some intuition on how the KL divergence behaves then returning to the original example involving two normal distributions. Observe that:
- When is large, but is small, the divergence gets very big. This corresponds to not covering well with
- When is small, but is large, the divergence is also large, but not as large as in (1). This corresponds to putting where is not.
I have again plotted the normal distributions from the beginning of this post, but am now including the raw value of the KL divergence as well as its value at each point.
approx_norm_middle = stats.norm.pdf(x, loc=0, scale=4)
middle_kl = stats.entropy(two_norms, approx_norm_middle)
middle_pointwise_kl = scipy.special.kl_div(two_norms, approx_norm_middle)
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
plt.plot(x, two_norms, label='P=(N(-3, 1) + N(3, 1))/2')
plt.plot(x, approx_norm_middle, label='Q=N(0, 4)')
plt.plot(x, middle_pointwise_kl, label='KL Divergence', linestyle='-')
plt.title(f'Approximate two Guassians with one in the center, KL={middle_kl:.4f}')
plt.legend()
plt.subplot(1, 2, 2)
approx_norm_side = stats.norm.pdf(x, loc=3, scale=2)
side_kl = stats.entropy(two_norms, approx_norm_side)
side_pointwise_kl = scipy.special.kl_div(two_norms, approx_norm_side)
plt.plot(x, two_norms, label='P=(N(-3, 1) + N(3, 1))/2')
plt.plot(x, approx_norm_side, label='Q=N(3, 2)')
plt.plot(x, side_pointwise_kl, label='KL Divergence', linestyle='-')
plt.title(f'Approximate two Guassians by covering one more than the other, KL={side_kl:.4f}')
plt.legend()
plt.show()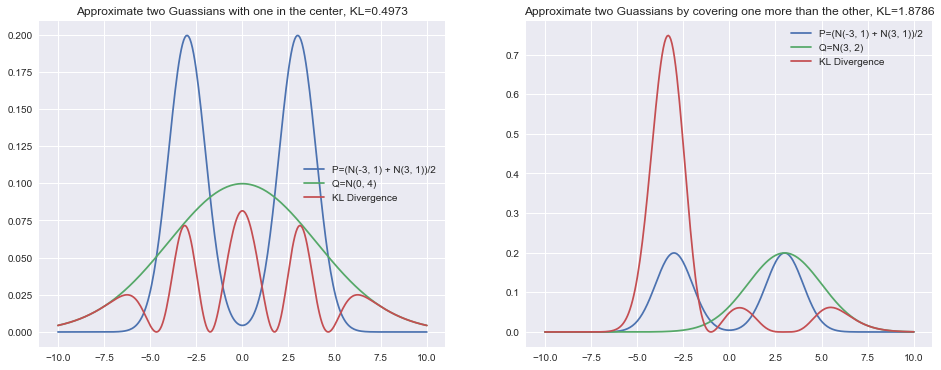
By looking at this its now easy to see how properties (1) and (2) play out in practice. The KL divergence is much happier with the solution on the left since is always at least partially covered. It is comparatively unhappy with the right solution since it leaves the left normal mode uncovered. Thus, in general the KL divergence of approximated with prefers to average out modes.
One increasingly common use case for the KL divergence in machine learning is in Variational Inference. For a number of reasons, the optimized quantity is the KL divergence of approximated by written as . The KL divergence is not symmetric so the behavior could be and in general is different. I have drawn the same normal distributions but instead this time using this alternative use of the KL divergence.
approx_norm_middle = stats.norm.pdf(x, loc=0, scale=4)
middle_kl = stats.entropy(approx_norm_middle, two_norms)
middle_pointwise_kl = scipy.special.kl_div(approx_norm_middle, two_norms)
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
plt.plot(x, two_norms, label='P=(N(-3, 1) + N(3, 1))/2')
plt.plot(x, approx_norm_middle, label='Q=N(0, 4)')
plt.plot(x, middle_pointwise_kl, label='KL Divergence', linestyle='-')
plt.title(f'Approximate two Guassians with one in the center, KL={middle_kl:.4f}')
plt.legend()
plt.subplot(1, 2, 2)
approx_norm_side = stats.norm.pdf(x, loc=3, scale=2)
side_kl = stats.entropy(approx_norm_side, two_norms)
side_pointwise_kl = scipy.special.kl_div(approx_norm_side, two_norms)
plt.plot(x, two_norms, label='P=(N(-3, 1) + N(3, 1))/2')
plt.plot(x, approx_norm_side, label='Q=N(3, 2)')
plt.plot(x, side_pointwise_kl, label='KL Divergence', linestyle='-')
plt.title(f'Approximate two Guassians by covering one more than the other, KL={side_kl:.4f}')
plt.legend()
plt.show()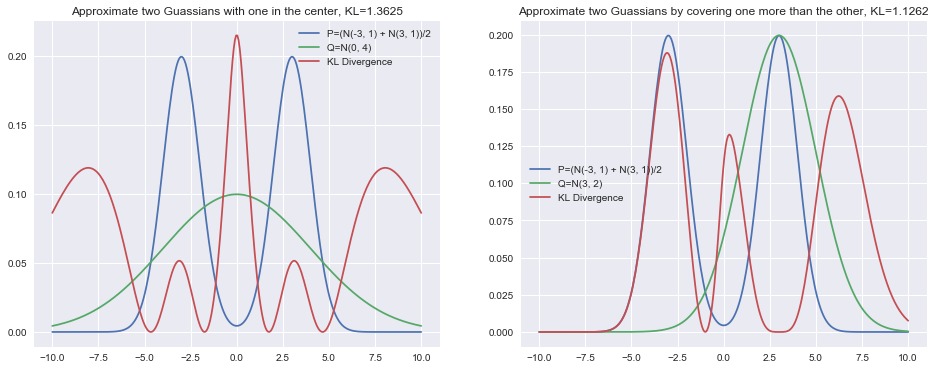
The behavior of the KL divergence here is quite different. It will specifically punish when there is mass in , but not in . This can be seen in the center of the left plot. It will also not punish as heavily when there is mass in , but not in as seen in the right plot. The left normal distribution’s KL divergence is comparatively much smaller than before.
There are many uses for the KL divergence so I hope that this post was enlightening in building up the concept from the ground up!